Contents
Tags
Best Local LLMs for Coding in 2026
Code-focused LLMs have improved dramatically. The best open-source coding models now rival GPT-4o on standard benchmarks — and running them locally means zero API costs, full privacy for your codebase, and no rate limits.
Top Picks at a Glance
- ▸Best overall: Qwen2.5 Coder 32B — leads HumanEval, strong at multi-file context
- ▸Best for 8GB VRAM: DeepSeek Coder 6.7B — punches far above its weight class
- ▸Best for completions: Codestral 22B — built specifically for IDE integration
- ▸Best reasoning + code: DeepSeek-R1 Distill (Qwen 14B) — excels at hard algorithmic problems
- ▸Best for 4GB VRAM: Phi-4 Mini — surprisingly capable for its size on Python/JS
Qwen2.5 Coder 32B — Best Overall
Alibaba's Qwen2.5 Coder 32B scores 92.7 on HumanEval and 75.1 on MBPP+ — matching or beating GPT-4o on most coding benchmarks. It handles 128K context, making it practical for large codebase work. At Q4 you need ~20GB VRAM.
DeepSeek Coder V2 — Best Value
The 16B variant runs in 10-12GB VRAM at Q4 and scores 90.2 on HumanEval. DeepSeek Coder V2 is particularly strong on Python, Go, and Rust. The 236B MoE variant is the gold standard if you have the hardware for it.
Codestral 22B — Best for IDE Integration
Mistral's Codestral was built from the ground up for fill-in-the-middle (FIM) completions — the same technique used by GitHub Copilot. It works natively with Continue.dev, Cursor, and the Mistral API. 12-14GB VRAM at Q4.
For IDE autocomplete, latency matters more than raw benchmark scores. Smaller models (7B-16B) at Q4 on a fast GPU will feel snappier than a 32B model that takes 2 seconds per token.
Benchmark Comparison
- ▸Qwen2.5 Coder 32B: HumanEval 92.7 | MBPP+ 75.1 | LiveCodeBench 43.8
- ▸DeepSeek Coder V2 16B: HumanEval 90.2 | MBPP+ 71.3 | LiveCodeBench 38.2
- ▸Codestral 22B: HumanEval 88.4 | MBPP+ 68.9 | FIM Score 94.1
- ▸CodeLlama 70B: HumanEval 85.3 | MBPP+ 63.4 | LiveCodeBench 31.7
- ▸Phi-4 Mini (3.8B): HumanEval 73.1 | MBPP+ 55.2 | Best-in-class for size
How to Run Them with Ollama
# Qwen2.5 Coder 32B (needs ~20GB VRAM at Q4)
ollama run qwen2.5-coder:32b
# DeepSeek Coder 6.7B (8GB VRAM)
ollama run deepseek-coder:6.7b
# Codestral 22B
ollama run codestral:22b
# Check what's running
ollama psFind the Right Model for Your GPU
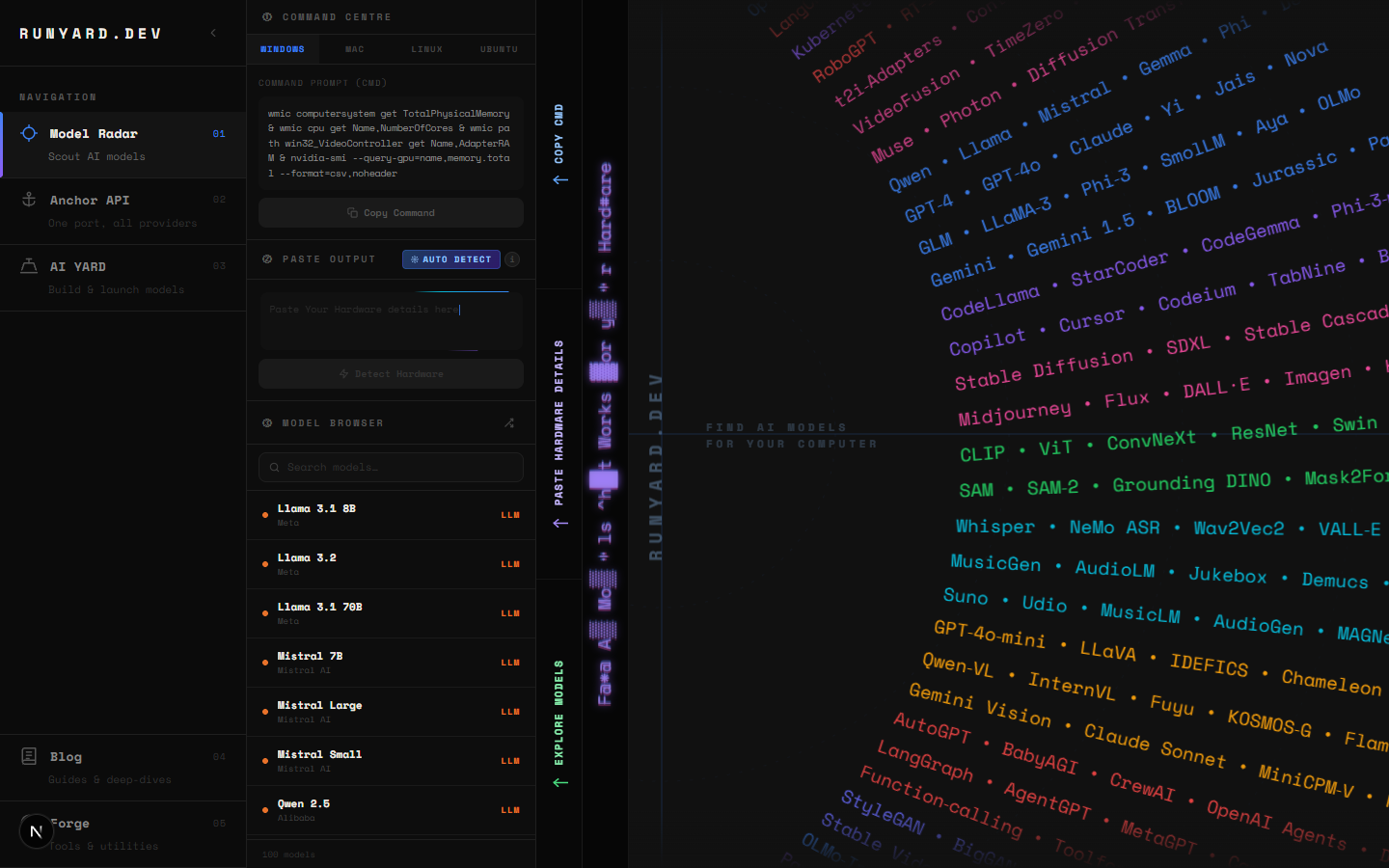
Use Runyard's Model Radar at runyard.dev to instantly filter coding models by your available VRAM. It shows real-world performance estimates and quantization options for your exact GPU — so you don't download a 20GB model only to find out it doesn't fit.
Tools
Newsletter